Git 基础 简单地说,Git 究竟是怎样的一个系统呢? 请注意接下来的内容非常重要,若您理解了 Git 的思想和基本工作原理,用起来就会知其所以然,游刃有余。
直接记录快照,而非差异比较 Git 和其它版本控制系统(包括 Subversion 和近似工具)的主要差别在于 Git 对待数据的方法。 概念上来区分,其它大部分系统以文件变更列表的方式存储信息。 这类系统(CVS、Subversion、Perforce、Bazaar 等等)将它们保存的信息看作是一组基本文件和每个文件随时间逐步累积的差异。
Git 存储项目随时间改变的快照。存储项目随时间改变的快照.这是 Git 与几乎所有其它版本控制系统的重要区别。 因此 Git 重新考虑了以前每一代版本控制系统延续下来的诸多方面。 Git 更像是一个小型的文件系统,提供了许多以此为基础构建的超强工具,而不只是一个简单的 VCS。
近乎所有操作都是本地执行 在 Git 中的绝大多数操作都只需要访问本地文件和资源,一般不需要来自网络上其它计算机的信息。如果您习惯于所有操作都有网络延时开销的集中式版本控制系统,Git 在这方面会让您感到速度之神赐给了 Git 超凡的能量。 因为您在本地磁盘上就有项目的完整历史,所以大部分操作看起来瞬间完成。
举个例子,要浏览项目的历史,Git 不需外连到服务器去获取历史,然后再显示出来——它只需直接从本地数据库中读取。 您能立即看到项目历史。 如果您想查看当前版本与一个月前的版本之间引入的修改,Git 会查找到一个月前的文件做一次本地的差异计算,而不是由远程服务器处理或从远程服务器拉回旧版本文件再来本地处理。
这也意味着您离线或者没有 VPN 时,几乎可以进行任何操作。 如您在飞机或火车上想做些工作,您能愉快地提交,直到有网络连接时再上传。 如您回家后 VPN 客户端不正常,您仍能工作。 使用其它系统,做到如此是不可能或很费力的。 比如,用 Perforce,您没有连接服务器时几乎不能做什么事;用 Subversion 和 CVS,您能修改文件,但不能向数据库提交修改(因为您的本地数据库离线了)。 这看起来不是大问题,但是您可能会惊喜地发现它带来的巨大的不同。
Git 保证完整性 Git 中所有数据在存储前都计算校验和,然后以校验和来引用。 这意味着不可能在 Git 不知情时更改任何文件内容或目录内容。 这个功能建构在 Git 底层,是构成 Git 哲学不可或缺的部分。 若您在传送过程中丢失信息或损坏文件,Git 就能发现。
Git 用以计算校验和的机制叫做 SHA-1 散列(hash,哈希)。 这是一个由 40 个十六进制字符(0-9 和 a-f)组成字符串,基于 Git 中文件的内容或目录结构计算出来。 SHA-1 哈希看起来是这样:1 24b9da6552252987 aa493b52f86 96cd6d3b00373
Git 中使用这种哈希值的情况很多,您将经常看到这种哈希值。 实际上,Git 数据库中保存的信息都是以文件内容的哈希值来索引,而不是文件名。
Git 一般只添加数据 您执行的 Git 操作,几乎只往 Git 数据库中增加数据。 很难让 Git 执行任何不可逆操作,或者让它以任何方式清除数据。 同别的 VCS 一样,未提交更新时有可能丢失或弄乱修改的内容;但是一旦您提交快照到 Git 中,就再难丢失数据,特别是如果您定期的推送数据库到其它仓库的话。
这使得我们使用 Git 成为一个安心愉悦的过程,因为我们深知可以尽情做各种尝试,而没有把事情弄糟的危险。 更深度探讨 Git 如何保存数据及恢复丢失数据的话题,请参考“Undoing Things”。
三种状态 好,请注意。 如果您希望后面的学习更顺利,记住下面这些关于 Git 的概念。
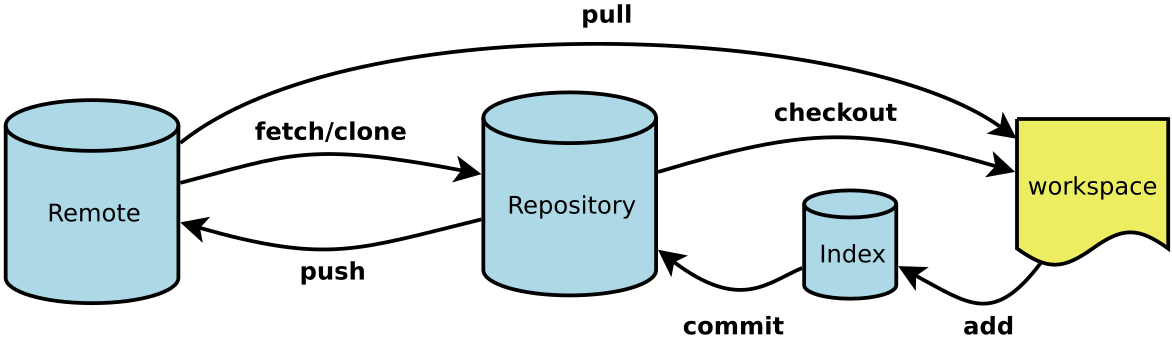
由此引入 Git 项目的三个工作区域的概念:Git 仓库、工作目录以及暂存区域。
每个项目都有一个 Git 目录(译注:如果 git clone 出来的话,就是其中 .git 的目录;如果 git clone –bare 的话,新建的目录本身就是 Git 目录。),它是 Git 用来保存元数据和对象数据库的地方。该目录非常重要,每次克隆镜像仓库的时候,实际拷贝的就是这个目录里面的数据。
从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从 Git 目录中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。
所谓的暂存区域只不过是个简单的文件,一般都放在 Git 目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
基本的 Git 工作流程如下:
Workspace :工作区Index / Stage :暂存区Repository :仓库区(或本地仓库)Remote :远程仓库
在工作目录中修改某些文件。
对修改后的文件进行快照,然后保存到暂存区域。
提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。
所以,我们可以从文件所处的位置来判断状态:如果是 Git 目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。到第二章的时候,我们会进一步了解其中细节,并学会如何根据文件状态实施后续操作,以及怎样跳过暂存直接提交。
安装Git 是时候动手尝试下 Git 了,不过得先安装好它。有许多种安装方式,主要分为两种,
一种是通过编译源代码来安装;
一种是使用为特定平台预编译好的安装包(yum | apt-get)。
WIN下自动Google,或去官网自行下载
初次运行 Git 前的配置 一般在新的系统上,我们都需要先配置下自己的 Git 工作环境。配置工作只需一次,以后升级时还会沿用现在的配置。当然,如果需要,你随时可以用相同的命令修改已有的配置。
Git 提供了一个叫做 git config 的工具(译注:实际是 git-config 命令,只不过可以通过 git 加一个名字来呼叫此命令。),专门用来配置或读取相应的工作环境变量。而正是由这些环境变量,决定了 Git 在各个环节的具体工作方式和行为。这些变量可以存放在以下三个不同的地方:
/etc/gitconfig 文件:系统中对所有用户都普遍适用的配置。若使用 git config 时用 –system 选项,读写的就是这个文件。~/.gitconfig 文件:用户目录下的配置文件只适用于该用户。若使用 git config 时用 –global 选项,读写的就是这个文件。.git/config 文件):这里的配置仅仅针对当前项目有效。每一个级别的配置都会覆盖上层的相同配置,所以 .git/config 里的配置会覆盖 /etc/gitconfig 中的同名变量。1 C:\Documents and Settings\$USER
此外,Git 还会尝试找寻 /etc/gitconfig 文件,只不过看当初 Git 装在什么目录,就以此作为根目录来定位。
用户信息 第一个要配置的是你个人的用户名称和电子邮件地址。这两条配置很重要,每次 Git 提交时都会引用这两条信息,说明是谁提交了更新,所以会随更新内容一起被永久纳入历史记录:1 2 $ git config --global user.name "sphenginx" $ git config --global user.email sphenginx@sphenginx.com
如果用了--global选项,那么更改的配置文件就是位于你用户主目录下的那个,以后你所有的项目都会默认使用这里配置的用户信息。如果要在某个特定的项目中使用其他名字或者电邮,只要去掉 –global 选项重新配置即可,新的设定保存在当前项目的 .git/config 文件里。
文本编辑器 接下来要设置的是默认使用的文本编辑器。Git 需要你输入一些额外消息的时候,会自动调用一个外部文本编辑器给你用。默认会使用操作系统指定的默认编辑器,一般可能会是 Vi 或者 Vim。如果你有其他偏好,比如 Emacs 的话,可以重新设置:1 $ git config --global core.editor emacs
差异分析工具1 $ git config --global merge .tool vimdiff
Git 可以理解 kdiff3,tkdiff,meld,xxdiff,emerge,vimdiff,gvimdiff,ecmerge,和 opendiff 等合并工具的输出信息。当然,你也可以指定使用自己开发的工具,具体怎么做可以参阅第七章。
查看配置信息 要检查已有的配置信息,可以使用 git config --list 命令:1 2 3 4 5 6 7 8 $ git config --list user.name=sphenginx user.email=sphenginx@gmail.com color .status=auto color .branch=auto color .interactive=auto color .diff=auto ...
有时候会看到重复的变量名,那就说明它们来自不同的配置文件(比如 /etc/gitconfig 和 ~/.gitconfig),不过最终 Git 实际采用的是最后一个。
https方式每次都要输入密码,按照如下设置即可输入一次就不用再手输入密码的困扰而且又享受https带来的极速:
设置记住密码(默认15分钟):1 git config --global credential.helper cache
如果想自己设置失效时间,可以这么设置:1 git config credential.helper 'cache --timeout=3600' //这样就设置一个小时之后失效
长期储存密码:1 git config --global credential.helper store
注:This [git-credential-cache] doesn’t work for Windows systems as git-credential-cache communicates through a Unix socket
The wincred helper was added in msysgit 1.8.1. Use it as follows:
1 git config --global credential.helper wincred
Finally, launch a command prompt and type:
1 git config --global credential.helper winstore
附:https 方式使用git@osc设置密码的方式
总结一下commit的几种姿势: 传统姿势:先 “git add file” 再 “git commit -m ‘xxx’ “
Git tips
设置config信息
1 2 3 $ git config --global user.name sphenginx $ git config --global user.email sphenginx@sphenginx.com $ git config --list
生成ssh key
1 ssh-keygen -t rsa -C "sphenginx@gmail.com"
查看config信息
彩色的 git 输出:
1 git config color .ui true
显示历史记录时,只显示一行注释信息:
1 git config format.pretty oneline
不替换win下的CRLF设置
1 git config core.autocrlf false
win下使用https地址的仓库不输入密码设置
1 git config credential.helper wincred
获取我的Github的PHP笔记仓库
1 git clone https ://github.com/sphenginx/sphenginx.git
设置远程仓库地址
1 2 3 4 git remote -v git remote --help git remote set origin https: //github.com /sphenginx/sphenginx.git git remote set -url origin https: //github.com /sphenginx/sphenginx.git
正常提交命令
1 2 3 4 5 git status git pull origin master git add .git commit -am '提交信息' git push origin master
缓存某些修改的文件
恢复缓存的文件
获取某个分支/恢复某个文件
1 git checkout branchX/file_path
撤销某次修改
回退到某个版本
可以在你的仓库根目录中添加一个叫”.gitignore”的文件,来告诉Git系统要忽略 掉哪些文件,下面是文件内容的示例:
1 2 3 4 5 6 7 8 9 # 以'#' 开始的行,被视为注释. # 忽略掉所有文件名是 foo.txt 的文件. foo.txt # 忽略所有生成的 html 文件, *.html # foo.html是手工维护的,所以例外. !foo.html # 忽略所有.o 和 .a文件. *.[oa]
删除 untracked files
连 untracked 的目录也一起删掉
连 gitignore 的untrack 文件/目录也一起删掉 (慎用,一般这个是用来删掉编译出来的 .o之类的文件用的)
在用上述 git clean 前,强烈建议加上 -n 参数来先看看会删掉哪些文件,防止重要文件被误删
1 2 3 git clean -nxfdgit clean -nf git clean -nfd
内建的图形化 git
More info git-scm.com
常用 Git 命令清单 - 阮一峰
GIT永久删除commit
如何在 Git 里撤销(几乎)任何操作
开源项目的那点事